Measure Twice, Cut Once
In a previous post, I observed that, as I increased the number of cores in my GPGPU, performance began to plateau and hardware threads spent more time stalled because their store queue was full. I speculated that the latter might cause the latter, although that wasn’t definitive. The current implementation only has a single store queue entry for each thread. One optimization I’ve been considering is adding more store queue entries, but this has subtle and complex design tradeoffs.
Current Implementation
I originally gave an overview of the design of the store buffer in this post. I will repeat some of that here, but go into much deeper detail to explore performance tradeoffs and constraints.
The level 1 (L1) data cache is “write through.” Cores send all memory stores to the shared level 2 (L2) cache. Using a write- through design simplifies cache coherence, but has more performance overhead. The store queue helps mitigate this. There is an independent store queue for each thread. When a thread performs a store, the store queue latches the address and data. The thread can continue executing without waiting for the store to finish.
The store queue (l1_store_queue.sv), despite being only 300 lines of SystemVerilog, is one of the more complex modules in the hardware design. This is because it needs to enforce a number of implicit consistency guarantees.
Each store queue entry can be in one of these states:
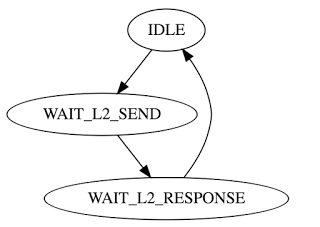
(These identifiers don’t appear in the HDL code: the state is encoded by each entry’s ‘valid’ and ‘request_sent’ bits. I only use these identifiers in this post for clarity).
A store is in the WAIT_L2_SEND state until the L2 cache has accepted it. It may need to wait more than one cycle in this state if other units are sending requests. There are three types of L2 cache requests a core can make: stores, load miss fills for the L1 instruction cache, and load miss fills for the L1 data cache. Each type can enqueue requests from four threads, and has an arbiter that selects one of them each cycle. Another 3 way arbiter selects one of the request types to send to the L2 cache.
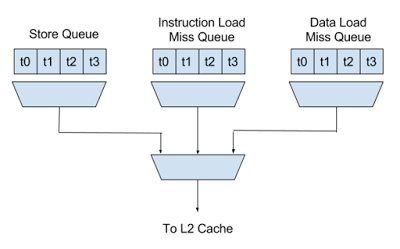
It is possible–although not likely–for a thread to have all three types of L2 requests pending. This means a core can have up to 4 threads * 3 requests = 12 requests pending. The L2 cache receives requests from all the cores, but can also only accept one request per cycle. There is another arbiter (for this test, 8 inputs) that selects one of the cores to process a request from. This means there can be up to 8 * 12 = 96 requests pending for the L2 cache.
There are two cases where the L2 cannot accept new requests:
- When the L2 cache needs to write back a cache line or load a new one, it puts the requests into queues. If those queues fill up, the L2 cache pipeline will stop accepting new requests.
- When the L2 cache fills a cache miss, it restarts the request that caused at the beginning of the L2 pipeline. During this cycle, it cannot accept requests from cores.
Once the L2 cache has accepted store request, it will be in the WAIT_L2_RESPONSE state until the L2 cache finishes processing the request and sends a response.
The first software visible effect of the way the store queue is implemented is that memory consistency is relaxed. Lets say we have two functions, each running on a different core:
volatile int a = 0;
volatile int b = 0;
void core1()
{
a = 1;
printf("b = %d", b);
}
int core2()
{
b = 1;
printf("a = %d", a);
}The output of this program is timing dependent. There are a few ways this could run:
- Both functions assign their variables, then both functions execute their prints. The output would be “a = 1 b = 1”
- core1 executes its print before core2 executes its assignment. The output is “b = 0 a = 1”
- core2 executes its print before core1 executes its assignment. The output is “a = 0 b = 1”
At first glance, it might not seem possible for this to output “a = 0 b = 0,” because at least one assignment must occur before either of the prints. But this can happen in this implementation if the variable stores are still in the store queue when the load occurs. This design can reorder stores after loads. But only between hardware threads. We guarantee that threads will always see _their own _stores in order. For example, this program would never print “a = 0.”
int a = 0;
void core1()
{
a = 1;
printf("a = %d", a);
}We can relax consistency between threads because it doesn’t affect program correctness when memory isn’t shared, and usually memory isn’t. But when it is, software needs a way to explicitly specify ordering. This design does that with a memory barrier. Here is the original program with barriers added:
volatile int a = 0;
volatile int b = 0;
void core1()
{
a = 1;
__sync_synchronize();
printf("b = %d", b);
}
int core2()
{
b = 1;
__sync_synchronize();
printf("a = %d", a);
}The __sync_synchronize built-in will, among other things, emit a ‘membar’ instruction on this architecture. The membar instruction suspends the thread until the L2 cache has acknowledged all pending stores for the thread. This ensures the new value of the memory location is visible to all cores. Because of this, it is longer possible for this to print “a = 0 b = 0,” because each thread must finish its store before printing the value.
Calling this design “write through” is misleading. It does not update the L1 data cache immediately when a store occurs. The store is first sent to the L2 cache. When the L2 finishes its update, it broadcasts a message to all cores to update their L1 caches if they contain that cache line. This updates the cache of the originator as a side effect. To ensure the thread sees its own stores before they are in the L1 cache, hardware checks the store queue in parallel with the cache every time it performs a load. If there is a store queued for the load address, it uses that data instead of the data returned from the L1 cache.
There’s a reason I don’t update the L1 cache immediately when the store occurs, even though it would remove the complexity of the bypass logic.
First off, doing this creates a new edge condition: a write update could come from the L2 cache the same cycle the core is performing a store. There are a few ways I could handle this:
- Add another write port to the L1 cache data array. This post discusses area and power impacts of this. I would still need to handle concurrent updates to the same cache line address.
- Roll the thread back and let the L2 cache update win. The thread would then need to retry its store later. This also adds complexity and runtime overhead.
But the most important reason is a subtle problem that would occur because hardware threads on the same core share an L1 data cache. In the next example, we have two functions that store a shared variable, and two functions that read it. Let’s assume writer1, writer2, and reader1 run on different cores:
volatile int a = 0;
void writer1()
{
a = 1;
}
void writer2()
{
a = 2;
}
void reader1()
{
while (1)
printf("1: a = %d ", a);
}
void reader2()
{
while (1)
printf("2: a = %d ", a);
}If writer 2 updates ‘a’ after writer 1, reader1 will print something like this sequence:
1: a = 0
1: a = 1
1: a = 2
But if reader2 is another hardware thread running on the same core as writer2, and stores updates the local cache immediately, it would be possible for it to print:
2: a = 0
2: a = 2
2: a = 1
2: a = 2
Here’s what is happening:
2: a = 0
Writer 2 updates the value to its local cache. It’s immediately visible to reader 2.
2: a = 2
L2 cache finishes processing store from writer 1 and broadcasts write update
2: a = 1
L2 cache finishes processing store from writer 2 and broadcasts write update
2: a = 2
This problem is unique to processors that support hardware multithreading.
While it looks odd that ‘a’ flips back to 1 from 2, the real problem is that reader1 and reader2 see the stores in different orders. This violates one of the three rules of cache coherence, as described by Patterson and Hennessy:
Writes to the same location are serialized; that is, two writes to the same location by any two processors are seen in the same order by all processors. For example if the values 1 and 2 are written to a location, processors can never read the value of the location as 2 and then later read it as one.
The WAIT_L2_RESPONSE state is necessary to enforce this ordering. If I didn’t need to, I could immediately make the store buffer entry available after the L2 has accepted the request. Supporting this ordering has a performance impact, because there are more cases where the thread cannot proceed because it is waiting for the store buffer entry to be available.
If the processor attempts a store and there is already one pending in the store queue, the thread will roll back and stall until the first store completes. But if the store is to the same cache line, the store queue may be able to “write combine” it. The store queue contains an entire 64 byte cache line. This allows it to perform a block vector store in a single cycle. In my first version of the design, the store queue was only 32-bits wide. It had identical performance to the current design for scalar stores. But it required 16 separate transactions to store a contiguous vector. I widened the store queue and internal busses to to improve memory performance.
Because it is possible to store values smaller than 64 bytes, the store queue also contains a mask, where each bit corresponds to a byte in the data field. These indicate that it should update that byte. The store queue entry is 64-byte aligned, so executing a 32-bit scalar store might look like this:

If another store for the same cache line comes in the store queue has sent it to the L2 cache, it will copy the new data into it. For example, after a second store, the store queue would contain:

If it has already sent the store queue entry to the L2 cache, it’s too late to write combine it. The thread rolls back and stalls.
The store queue also contains cache control commands like flushes and invalidates. These cannot be write combined with normal stores.
An Improved Implementation
To summarize, in the current design, a thread will stall waiting on the store queue when:
- A store is already pending for a different cache line.
- A store is pending for the same cache line, but the store queue has sent it to the L2 cache and is waiting for it to finish.
It’s hopefully clearer now how multiple store queue entries per thread could improve performance: When a store comes in and can’t be write combined with any existing entries, it would use a new one. It would stall only when all the entries are in-use. There are a few high order decisions for this design:
- What should it do when a thread attempts to load from an address that has a pending store in the store queue? * Use bypass logic to replace the cache data with the store data (current design), or * Roll back the thread and stall it until the store completes
- When the store queue has sent an entry to the L2 cache and is waiting for a response, can it send another, or should it wait for the first to complete?
- If the processor does a store that matches the address of a store buffer entry that it has already sent to the L2 cache (but not completed), and thus cannot write combine, does it: * Roll back and stall the thread until the store completes (current design), or * Put the store data into a new entry
We can’t consider these questions independently, because some design impacts result from the interaction between them. For example, if I answer question 1 by saying it should bypass entries, and answer question 3 by saying it should allocate a new entry, I’ll need to add logic to potentially bypass every single entry in the queue. Imagine something like this (I’m only showing 32 byte lanes to make this fit):
This implementation would need an n way mux for each of the 64 byte lanes in the store buffer (where n is the number of store queue entries). It would also need logic to determine the appropriate mux sources using modulo wrapping logic. That is much more complex and will have combinational delay that may affect clock speed. Changing only one of these decisions will avoid this.
A potential advantage to allowing multiple L2 requests to be pending (question 2) is that it could increase throughput, since the store queue could enqueue one request per cycle in the best case.
- But, as I’ve seen in the past, this advantage may go away when multiple hardware threads are running, because they hide the latency.
- Also, threads don’t store that often even in memory heavy applications, which erodes the improvement even more.
This system is complex enough that it’s perhaps impossible to predict the performance with real workloads without simulating it somehow. The definitive way to answer these questions would be to implement all all eight combinations and benchmark them against each other, but that would be a lot of work.
Rather, I can gather enough data with the existing design and make some educated guesses. The challenge is that the results are often workload dependent, and running the wrong test program may give me a misleading answer. Nonetheless, some assumptions are safer to make. For example, the fact that processors use caches is based on the assumption that memory accesses exhibit locality. It’s easy to write a program that violates that assumption–by accessing random locations, for example–and performs poorly on any modern processor, but we’re willing to accept that for the substantial performance improvement in more common use cases.
Gathering Data
Testing question 1 (how to handle loads when stores are pending) is straightforward. The beauty of HDL simulation is that it’s easy to add code to perform event and performance logging. I added this to writeback_stage.sv:
int total_loads;
int loads_bypassed;
always_ff @(posedge clk, posedge reset)
begin
if (reset)
begin
total_loads <= 0;
loads_bypassed <= 0;
end
else
begin
if (dd_instruction_valid && !dd_instruction.is_cache_control
&& dd_instruction.is_load && !wb_rollback_en)
begin
total_loads <= total_loads + 1;
if (sq_store_bypass_mask != 0)
loads_bypassed <= loads_bypassed + 1;
end
end
end
final
begin
$display("%0d total loads %0d bypassed", total_loads, loads_bypassed);
endI ran the ‘clip’ render test that I used to test scalability in the blog post cited at the beginning of this one. But, unlike that test, I ran it with one core and the default cache size. It gave this output:
ran for 26857296 cycles
***HALTED***
2746823 total loads 1024 bypassed
The low bypass count (0.037% of loads) was a surprise, although I guess it makes sense that the compiler tries to keep things in registers and it would be inefficient for it to load something it just wrote. This suggests, at least in the current design, the load bypass logic is overkill and rolling back the thread in this case would have minimal performance impact. A caveats is that, if there are more store buffers, there are more possibilities for a load conflict. However, it’s hard to imagine this being significantly higher.
The answer to question 2 depends on timing of stores. Stores can be write combined when the entry is in WAIT_L2_SEND from the state diagram earlier, but cannot be write combined in WAIT_L2_RESPONSE, because it has already sent the data to the L2 cache. It would be useful to know how much time store entries spend in these states. If they spend most of their time in WAIT_L2_RESPONSE and little in WAIT_L2_SEND, then it would make sense to add later stores to new entries, because there would be few opportunities for write combining.
I added code to the store buffer to log the amount of time pending entries spend in these states:
genvar thread_idx;
generate
for (thread_idx = 0; thread_idx < `THREADS_PER_CORE; thread_idx++)
begin : thread_store_buf_gen
...
+ int cycles_wait_send = 0;
+ int cycles_wait_response = 0;
+ int store_count = 0;
+
+ always @(posedge clk, posedge reset)
+ begin
+ if (reset)
+ begin
+ cycles_wait_send <= 0;
+ cycles_wait_response <= 0;
+ store_count <= 0;
+ end
+ else
+ begin
+ if (rollback == 0 && store_requested_this_entry)
+ store_count <= store_count + 1;
+
+ if (pending_stores[thread_idx].valid)
+ begin
+ if (pending_stores[thread_idx].request_sent)
+ cycles_wait_response <= cycles_wait_response + 1;
+ else
+ cycles_wait_send <= cycles_wait_send + 1;
+ end
+ end
+ end
+
+ final
+ begin
+ $display("%0d,%0d,%0d",
+ cycles_wait_send, cycles_wait_response, store_count);
+ endThis will print a separate line for each thread because it’s in a generate loop. For example:
ran for 19732 cycles
***HALTED***
7774,3094,441
7719,1959,305
7150,1750,304
7343,1792,306
...
For the following benchmarks, I average the results from all threads together. I ran a few tests to confirm these assumptions using a few limiting cases:
- A single thread writes a piece of cached memory repeatedly. This should be the best case (from a store buffer perspective) because there is no external memory transfer or contention among threads to access the L2 cache.
- All threads access a piece of cached memory repeatedly. There is contention among threads so they should spend most of their time in WAIT_L2_SEND.
- Writing memory as quickly as possible. The bottleneck is external memory and it should spend most time in WAIT_L2_RESPONSE.
Single Thread Writes Cached Memory.
This program uses a single thread to write to cached data in a loop. It writes two addresses on different cache lines to ensure the store buffer doesn’t combine the writes. I unroll the loop to minimize branch/loop overhead and ensure it’s writing as quickly as possible.
for (i = 0; i < 100; i++)
{
*((volatile int*) region_1_base) = 0x12345678;
*((volatile int*) region_2_base) = 0x12345678;
*((volatile int*) region_1_base) = 0x12345678;
*((volatile int*) region_2_base) = 0x12345678;
*((volatile int*) region_1_base) = 0x12345678;
*((volatile int*) region_2_base) = 0x12345678;
// (20 writes total)
}The results:
Total cycles: 31,542
Total stores: 2,137
Total cycles in WAIT_L2_SEND: 2,139
Total cycles in WAIT_L2_RESPONSE: 11,194
Total cycles with store pending: 13,333
Portion of time store buffer is pending: 42%
Total cycles per store: 13,333 / 2,137 = 6.2
Cycles in WAIT_L2_SEND per store: 2,139 / 2,137 = 1
Cycles in WAIT_L2_RESPONSE per store: 11,194 / 2,137 = 5.2
It takes 1 cycle to send each store request. They don’t need to wait in WAIT_L2_SEND because there’s only one writer.
In the case of a L2 cache hit, the L2 response takes 5 cycles. This is the best case: the length of the L2 pipeline (4 stages) plus one stage in the core that handles the L2 response. The cycles in WAIT_L2_RESPONSE is pretty close to that number. It is slightly higher probably because of initial cache misses when the program starts.
All Threads Access Cached Memory
This test is the same as the last one, but I enable all 8 cores and 32 threads running the loop above, writing to the same locations:
Total cycles: 22,529
Total stores/thread: 418
Total cycles in WAIT_L2_SEND/thread: 9,726
Total cycles in WAIT_L2_RESPONSE/thread: 2,421
Total cycles with store pending/thread: 12,147
Portion of time store buffer is pending: 54%
Total cycles per store: 29.05
Cycles in WAIT_L2_SEND per store: 23.27
Cycles in WAIT_L2_RESPONSE per store: 5.79
The cycles in WAIT_L2_RESPONSE is still around 5, because these are all cache hits. The total cycles for each L2 request is 29. In the best case, this would be 31, because each thread would wait for all other threads to execute before continuing, but it’s smaller presumably because of other overhead (for example, a thread misses its window because it’s just rolling back on a branch).
WAIT_L2_SEND is only 23 cycles (rather than 28) because when it enqueues its request, there are already around 5 store requests somewhere in the L2 request/response pipeline.
Write Memory as Fast as Possible
I modified the membench benchmark to only run the write test. I only used one core with four threads. Each of the thread uses block vector writes to push 64 bytes at a time in an unrolled loop. I configured this with a 128k cache. After it writes the first 128k, every subsequent write will cause it to flush another cache line, so it will be writing continuously.
Total Cycles: 975,515
Total cycles in WAIT_L2_SEND/thread: 8,298
Total cycles in WAIT_L2_RESPONSE/thread: 906,812
Total cycles with store pending/thread: 915,067
Total stores/thread: 8,255
Portion of time store is pending: 93.8%
Cycles per store: 111.9
Cycles in WAIT_L2_SEND per store: 1.005
Cycles in WAIT_L2_RESPONSE per store: 110.85
As expected, the stores spend all their time in WAIT_L2_RESPONSE. For an L2 cache miss, WAIT_L2_RESPONSE takes an undefined number of cycles, which depends on the number of other queued L2 cache misses and latency to main memory.
For this case and the last one, adding more store queue entries would not improve performance, because they are hitting bottlenecks. Adding more entries helps where we aren’t hitting a bottleneck, but are underutilizing hardware because of variable latencies.
Mixed Use Case
With that established, I can rerun ‘clip’ test I mentioned earlier with the new instrumentation. This is the chart from the post I cited at the beginning of this one that prompted this investigation.
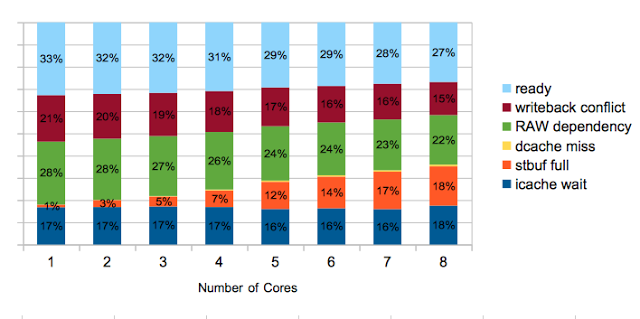
For this test, I’m running on 8 cores, 32 threads total. The original experiment increased the size of a 4MB L2 cache. The default cache size for one core is 128k. This would thrash with 32 threads rendering separate tiles. To remove another variable, I had increased the size so the entire working set would fit in the cache. I’ve done the same here, but this means the time spent waiting for L2 transactions to complete is going to be small and may not represent other workloads.
Here are the results:
Total cycles: 4,603,805
Total stores/thread: 79,745
Total cycles in WAIT_L2_SEND/thread: 502,121
Total cycles WAIT_L2_RESPONSE/thread: 502,859
Total cycles waiting on store buffer/thread: 1,004,980
Portion of time store is pending: 21.8%
Average cycles wait per store: 12.6
Cycles in WAIT_L2_SEND per store: 6.3
Cycles in WAIT_L2_RESPONSE per store: 6.3
The number of cycles waiting for the L2 response is around 6, somewhat higher than the best case, cache-hit latency of 5 cycles, but close enough to support the assumption that the L2 cache is large enough to contain the entire working set. WAIT_L2_SEND is just over 6 cycles, so there is contention for the L2 cache because so many threads are performing stores.
There are about 2.5 million stores across all threads. I added a counter to tally how many stores it combined, which reported 250k, 9.7% of the total. There would be more opportunities for write combining if there were multiple store buffer entries, but is unclear how much.
This means there are 2,303,933 total L2 stores requests. Since each of these takes one bus cycle, this consumes about half of the L2 bandwidth.
So, would adding store buffer entries improve the performance of this test much? The fact that threads are waiting 6 cycles to send to the L2 interface, yet the L2 interface is busy less than half the time (this includes other response types, which I measured in the original post) suggests yes. It takes several cycles for a thread to restart and queue another store request when it wakes. If that request were already queued, it could issue it immediately. Allowing a thread to continue executing when it has issued a store would allow them to run more often and get on with useful work. The question is how much it would help, and that’s hard to calculate directly.
Conclusions
Going back to the three questions I asked earlier:
-
What should it do when a thread attempts to load from an address that has a pending store in the store queue?
The measurements suggest it should roll back the thread. Loads after stores are infrequent so there isn’t a performance win, and it simplifies the implementation not to bypass them.
-
When it has sent an entry to the L2 cache and is waiting for a response, can it send another, or should it wait for the first to complete?
It is easier to make it send one at a time, and it’s not clear there is a big performance win having multiple stores pending.
-
If the processor does a store that matches the address of a store buffer entry that it has already sent to the L2 cache (but not completed), and thus cannot write combine, what does it do:
This is fuzzier. The data from my last test showed that entries spend at least 50% of their time in the WAIT_L2_RESPONSE state, and 20% even in the best case. But only 10% of transactions are write combined for the test workload. This may increase with more store buffer entries. The incremental complexity of doing this seems to be moderate at first blush, so it’s worth implementing and testing.
I don’t know how much of a performance win this design change would net. It doesn’t seem like a clear win. Unfortunately, it’s not easy to know the implications of a non-trivial design decision without implementing and testing it with complex workloads.