Closures
A while back, I built a Lisp machine that runs on FPGA. One feature that was lacking was support for lexical closures. I used some extra time over the recent break to add support for them.
Full source code is here:
https://github.com/jbush001/LispMicrocontroller
Background
One inspiration for this project was an MIT AI Memo that describes a machine that natively runs a dialect of Scheme, AIM 514 “Design of LISP-Based Processors or SCHEME: A Dielectric LISP or Finite Memories Considered Harmful or LAMBDA: The Ultimate Opcode.”
This paper challenged some assumptions I had about how processors had to operate. Rather than using a traditional program counter, it represented code as expressions in linked lists. It also used a linked list to store the local environment, rather than a contiguous stack. In modern processors, there is a large gap between the high level language and the low level code that the compiler generates, but in this design, machine code is close to the source language.
My implementation differs in some fundamental ways from the one described in this paper:
- I store my program as an array of instructions rather than in lists. Using lists as the processor described in this paper did was an unorthodox choice, and subsequent commercial lisp machines did not follow this approach (the CADR machine, for example)
- I use lexical rather than dynamic scoping and store the environment on a stack rather than as a list of variables. Closures only exist in lexically scoped languages.
- I use random logic for the state machine rather than microcode.
- I implement memory allocation and garbage collection in Lisp in the runtime library rather than in microcode. The processor described in the paper needs to perform memory allocation and garbage collection in hardware since it needs to allocate memory to call a function.
Another inspiration was the J1 Forth CPU. It’s beautifully simple: the core is only 131 lines of Verilog. The hardware supports a small number of primitive Forth words. The rest of the interpreter is built–in Forth–on top of that.
Forth and Lisp are similar in their extreme adherence to a pure, minimal programming model. The execution environments are also largely built in the language itself, using metaprogramming features on top of a small set of native primitives. This makes is easy to run them on simple hardware implementations.
Implementation
I won’t describe the whole implementation here, but detailed documentation is available in the project wiki. I’ll review a few relevant aspects.
Unlike most Lisp interpreters, my processor doesn’t support a REPL (read/evaluate/print loop). A compiler (compile.py) builds the program on a host machine and preloads into instruction memory on the device.
This is a Harvard architecture. It has two memories: one for instructions and the other for data. Because this is a microcontroller, and these are internal memories, I could make them non-standard widths. Instruction memory is 22 bits wide. Each instruction stores a 5 bit opcode and a 16 bit operand:

Data memory is 19 bits wide. Each location in data memory stores a 16 bit value, 2 bit tag that identifies the data type, and a 1 bit value used during garbage collection.
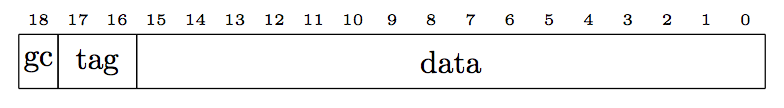
There are four types of tags:
| Tag | Type |
|---|---|
| 00 | 16-bit integer value |
| 01 | Cons cell |
| 10 | Function pointer |
| 11 | Closure |
For a cons cell, the tag is in the thing that points to the cons cell, not in the cell itself (each element in the cell has its own tag that determines the type of that element).
The data address space is laid out as follows:
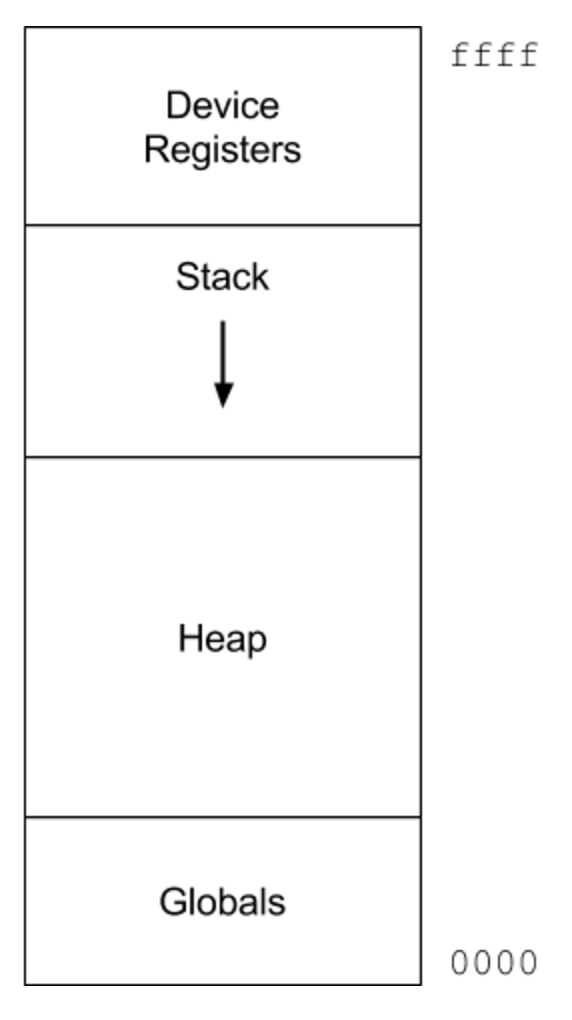
The stack starts at the top of addressable memory and grows downward. Global variables are at the beginning of memory. The heap starts immediately after the globals. The sole unit of allocation in this system is a cons cell, which has two elements. Using fixed sized elements simplifies the allocator, since it doesn’t need to worry about compaction and fragmentation. It uses a simple mark/sweep garbage collector.
Three machine internal processor registers hold the machine state: the stack pointer, the frame pointer, and the program counter. This is a stack machine: All instructions use stack memory operands: they pop the source operands off the stack and push the result back on the stack. For example, this expression performs the ‘add’ function on the value of the variable a and the number four:
(add a 4)
The compiler generates the following instructions (it pushes operands right-to-left)
push 4
getlocal 1
add
The getlocal instruction copies a value from the environment and pushes it on the stack.
Each time the program calls a function, it builds a stack frame data structure onto the stack and updates the frame pointer register to this new frame.
The highest address is on top and new entries are pushed on the bottom
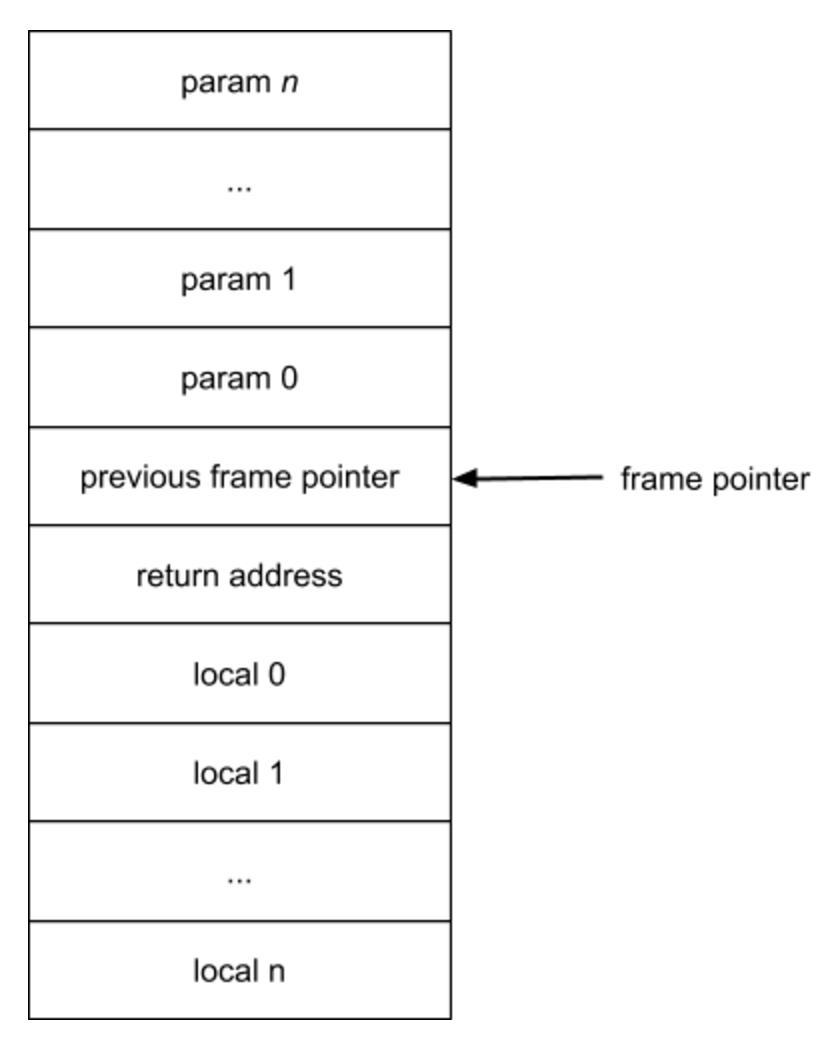
The getlocal instruction operand is an offset relative to the frame pointer: negative offsets point to local variable slots and positives to parameters.
The Problem
The stack based system is simple and easy to generate code for. But a problem becomes evident in the following code:
(function make_add (x)
(function (y) (+ x y))The function make_add returns another function that takes a single parameter. But the inner function references x. After made_add returns, the stack space that held x is no longer valid.
I need a some way to bundle the value x with the function and pass the whole thing around like any other value. I can do that by creating a closure.
A Solution
When the compiler encounters the inner function, it doesn’t generate the code inside the enclosing function. Instead it makes another top level function and emits a reference to that function inside the enclosing one. So the generated code looks something like this:
<anonymous function>: <--- inner function
0368 reserve 2
...
make_add:
...
0401 push 368 <--- pointer to inner function
...When looking up a symbol, it first searches through the local environment within the function. If it does not find the value, it steps up to the enclosing function (if present) and looks there. If it does find the variable (for example, ‘low’ in this program) in the outer environment, it does a few things:
- Create a new symbol in the scope of the inner function to represent the free variable.
- Add a reference in this symbol object that points to the symbol in the enclosing function.
- Add the symbol to a list of free variables associated with the inner function.
I didn’t make any hardware changes for this feature. The compiler generates code in three places to support closures:
Create the Closure
When the compiler finishes compiling the inner function, it checks it to see if it has free variables. If so, it emits code in the enclosing function to copy the values from the local environment into a linked list. The closure is a cons cell where the first element contains a pointer to the function code in instruction memory and the second points to the list of all free variables it just created. As mentioned above, all memory locations have a tag to mark their type. The tag for this node marks it as a closure.
The end result looks like this:
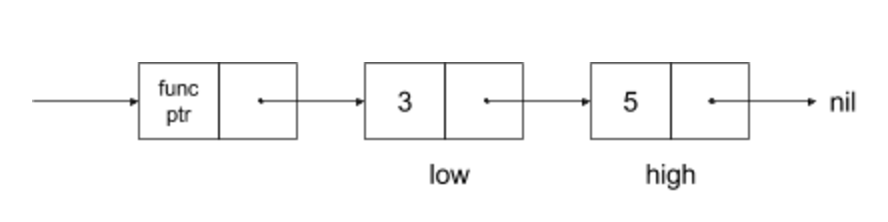
Call the Closure
When calling a function through a pointer, the code must first determine if this is a bare function or closure (the bare function is an optimization and doesn’t need to unpack the closure structure).
If the called object is a closure, it needs to:
- Read the second element in the closure cell. Store it in a special global variable $closure.
- Read the first element in the closure cell and push on the stack. This is the address to jump to.
- Invoke the call instruction
Enter the Inner Function
The compiler inserts code into the prologue of the inner function to unpack the closure variables from the list.
- Read the pointer to the environment list from the variable $closure (which the caller set before jumping to the function)
- For each cons cell in the list, read the value from the first element and perform a SETLOCAL instruction to save it in the appropriate local variable.
Errata
There is a subtle issue with the way I’ve implemented closures. To understand this better, let’s play with closures in Javascript:
function make_closure() {
var x = 0;
return function() {
console.log(x);
x++;
}
}
var func = make_closure();
func();
func();
func();When I run this in the browser debugger, it outputs the following:
0
1
2
The variable lives inside the closure. The program updates the closure variable, so the new values are visible when it calls the closure again. Let’s try a similar version in my interpreter:
(function make_closure ()
(let ((x 0))
(function ()
(begin
(print x)
(assign x (+ x 1))))))
(assign func (make_closure))
(func)
(func)
(func)When I run this, instead I get:
0
0
0
That’s because my implementation copies the values into the local environment and discards them when it returns. I’m capturing by value, not reference.
Capture by reference also allows closures to communicate with each other. For example:
function init_functions() {
var funclist = [];
var shared = 0;
for (var i = 0; i < 3; i++)
funclist.push(function(){console.log(shared++);})
return funclist;
}
funclist = init_functions();
for (var i = 0; i < 3; i++)
funclist[i]();Each time a closure increments ‘shared’, all other closures see it. This outputs:
0
1
2
Here’s the same for my processor:
(function init_functions ()
(let ((funclist nil) (i 0) (shared 0)
(for i 0 2 1
(assign funclist (cons (function ()
(print shared)) funclist))
funclist))
(foreach func (init_functions)
(func))It prints
0
0
0
Since each closure has captured its own copy.
Most Lisps capture by reference and behave like Javascript in these examples. Swift behaves this way by default, but allows the programmer mark variables as capture-by-value using a capture list. C++11 has a similar mechanism.
It is possible to share variables between closures on my architecture, but the programmer needs to do it manually:
(function init_functions ()
(let ((funclist nil) (sharedref (cons 0 0)))
(for x 0 2 1
(assign funclist (cons (function ()
(setfirst sharedref (+ (first sharedref) 1))
(print (first sharedref))) funclist)))
funclist))
(foreach func (init_functions)
(func))This outputs
0
1
2
This creates a cons cell to contain the value. The reference to this cell is passed by value. It needs to access it indirectly using (setfirst sharedref …) to write it and (first sharedref) to read it.
A challenge with supporting capture-by-reference behavior automatically in my compiler is that it generates code in a single pass. At the point it recognizes that a variable is a closure variable, it may have already generated code in the enclosing function that accesses it like a normal stack variable.
One approach I considered was adding an intermediate pass to identify free variables. I sort of support multiple passes already: the parser converts the source code into a set of python lists, which it eventually recursively walks to generate code. But before that, I run an optimization pass on this structure to perform constant folding, on it. The nice thing about Lisp is that the source code is already pretty close to intermediate code, so it’s easy to perform transformations on. I could add another pass that replaces the string names with symbol objects, which have additional information to indicate free variables.
The Lua interpreter has a clever solution to this problem that doesn’t require a separate compiler pass, which I’ll talk about in the future.