Write Back vs. Write Through Bake Off
In the last update, I was debating whether the complexity of a write-back cache was justified by the performance increase. I ran a little bake-off between the version 1 microarchitecture, which uses a write through L1 cache, and the in-progress version 2 using a write-back L1 cache. There are many other differences between the architectures which would affect performance, but I’m going to focus on memory access patterns, which should be similar. I used the same teapot benchmark as in previous posts, as it has a nice mix of memory accesses. Both versions are running one core, so there are aspects of cache coherence traffic that aren’t captured, but I’ll get to that in a minute.
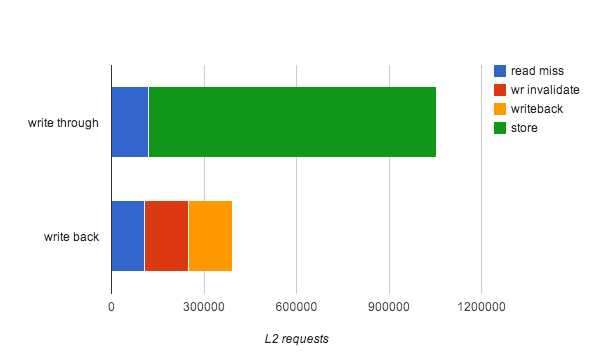
In this chart, the top bar represents the version 1 write through architecture. The number of read misses are roughly comparable. The green represents memory write instructions. As mentioned previously, all memory writes go through the L2 cache and thus consume interconnect bandwidth.
The bottom bar represents the version 2 write-back architecture. In this case, the green bar has been replaced by the red and orange parts. A write invalidate occurs when the cache line is not present in the l1 cache, or when it is the cache in the shared state and needs to be promoted to the exclusive state in order to be writable. The orange bar represents writebacks of dirty lines that were flushed or evicted from the L1 cache.
Overall, for this use case, the write-back architecture reduces interconnect traffic by 62%. This presumably allows double the number of cores to share the same L2 cache, assuming the system is interconnect traffic bound.
However, this is somewhat an ideal case because it doesn’t cover cases where cache lines are shared. In the write-back architecture, whenever a core writes to a cache line, it must send a message to remove it from other caches. If those subsequently attempt to read the cache line again, they will cause a cache miss. This can occur either for addresses that are legitimately used for communication between threads or collateral damage due to “false sharing,” where unrelated variables happen to be on the same cache line as a shared variable. The performance of the write-through architecture does not change as sharing increases, because it essentially always assumes lines are shared.
This analysis is also potentially overly pessimistic about write through protocols. Write combining (which was not supported by the V1 architecture) can reduce the number of interconnect messages, more so if multiple store buffers are employed. However, this heavily dependent on usage patterns and it difficult to perform back-of-napkin estimates for.
In both tests the amount of interconnect traffic generated by each core is relatively low, a single core utilizes 7% of interconnect cycles for v1 and 2.4% for v2. Of course, this use case may not be fully representative. It would be useful to see how other workloads compare.